Context Rot: A Contrarian Take on the Million-Token Race
LLM performance degrades as context grows — even on simple tasks. The million-token race might be solving the wrong problem entirely.


TL;DR: A Chroma researcher's findings on "context rot" reveal that LLM performance degrades with longer inputs, even on simple tasks. Hinting that the million-token race might be solving the wrong problem.
The million-token illusion
In marketing, we love numbers. As a result, every new LLM release comes with a triumphant tagline: "Now with 1 million tokens!" "Gemini supports 10 million tokens!" "Process entire books in a single prompt!"
The context window race has reached impressive scales. Some models now handle up to two million tokens—equivalent to over 3,000 pages of text.
It sounds like magic, and let's be honest, technically it is! But the implied promise is debatable: "feed your model everything: all your documentation, entire conversation histories, complete codebases. Watch it reason flawlessly across unlimited context."
Chroma's findings on "context rot" challenge this narrative. Now, before diving into the research, it's worth noting that Chroma builds vector databases for retrieval. They have a clear vested interest in arguing that large context windows aren't the solution. While that doesn't invalidate their findings, it's important context for evaluating their perspective.
The needle in a haystack deception
The "needle in a haystack" benchmark is the industry's favorite proof that massive context windows work. Drop a random fact into a long document, ask the model to find it, and watch it succeed with flying colors.
But as the Chroma researcher pointed out, these benchmarks are designed to be easy. The question and answer often share lexical matches. The model just needs to find the exact phrase, not reason through ambiguity or handle real-world complexity.
There is widespread skepticism around standard LLM benchmarks. We have contamination from pre-training data, misalignment with real-world use cases, and too strong of a vested interest in gaming the metrics.
What the Chroma research shows
The Chroma team's findings are compelling. When they tested real-world scenarios, performance degraded as input length increased, even on tasks models handle perfectly at shorter lengths.
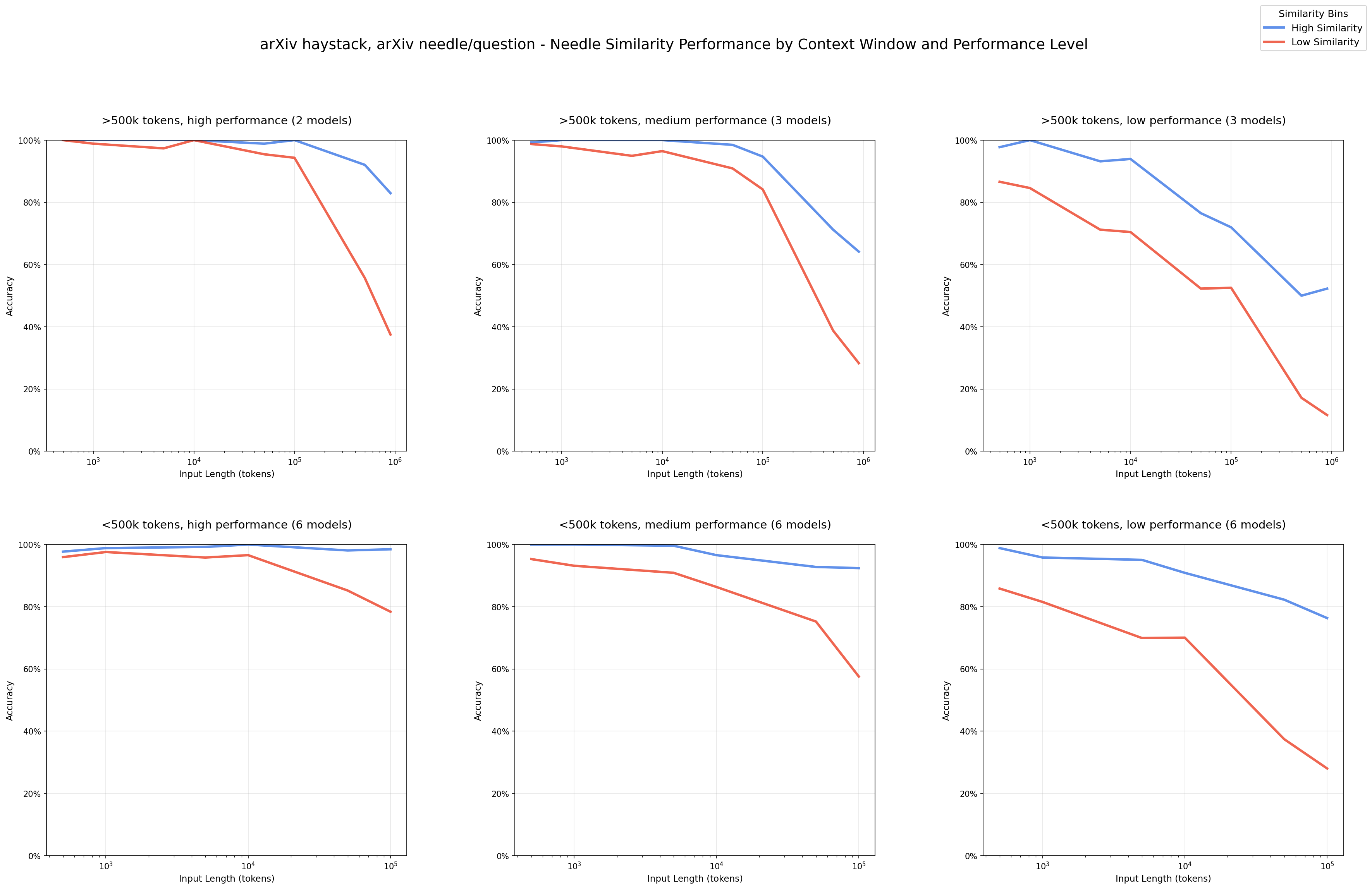
Performance degradation with input length
Here's what their research revealed:
Conversational memory breaks down
Building a chat assistant with memory sounds straightforward. User mentions they live in San Francisco early in the conversation, then asks for "good outdoor activities" later. The assistant should remember the location and suggest SF-specific recommendations.
The naive approach: dumping the entire chat history into the prompt, fails. When the Chroma team tested 500-message conversations (120k tokens), models performed significantly worse than when given only the relevant 300-token snippets.
Even advanced models struggle to find the right information when too much noise is present. This is not something new, this stanford research from 2023 found that performance degrades significantly when changing the position of relevant information, indicating that current language models do not robustly make use of information in long input contexts.
Ambiguity compounds the problem
Real-world questions aren't precise. When troubleshooting code, you don't specify exact lines, instead, as the vibecoder you've become, you say "fix this" and include a large chunk of your codebase.
As ambiguity increases, model performance degrades faster. At short inputs, models succeed even with the most ambiguous questions. This capability breaks down as input length grows.
Distractors become deadly
Distractors are information that's topically related but doesn't answer the specific question. In a conversation about writing advice, both "I got writing advice from my college classmate" and "I got writing advice from my high school classmate" might surface.
At short inputs, models can disambiguate. As input length grows, performance drops, even though the task itself remains unchanged.
Models aren't reliable computing systems
We expect LLMs to behave like programs: same input, same output. But when the researchers asked models to replicate a simple list of repeated words with one unique word inserted, they started failing even at 500 words. They would repeat beyond what was given or generate random outputs. By now, we now LLMs aren't deterministic but I'm not sure we've fully internalized the consequences.
Models don't process their context uniformly. They're not reliable computing systems in the way we might expect.
The Chroma perspective: context prompting over bigger windows
Based on their research, the Chroma team argues we need to engineer our context to get reliable performance. While you technically might be able to use a million tokens, they suggest your optimal context window is probably much smaller.
This becomes an optimization problem: maximize relevant information, minimize irrelevant context.
Personally, I love this! I've been on the bandwagon of using the terms "context prompting" for what most call "prompt engineering" and/or "context engineering". There isn't much engineering about it but the core value is really about providing the right context to the model.
The context prompting decision framework
Here's how I think about choosing between large context windows and context prompting:
Use large context windows when:
- You need to maintain conversation flow across long sessions
- The information is highly structured and relevant
- You're doing simple retrieval tasks (the "needle in a haystack" scenarios)
=> Think POC, single use...
Use context prompting when:
- You're building production systems that need reliable performance
- You're dealing with ambiguous queries or multiple distractors
- Cost and latency matter for your use case
There's no one-size-fits-all solution. What works for one application might fail for another. You need to experiment with your specific use case.
This is where Chroma argues the industry might be missing the point. Instead of racing to bigger context windows, they suggest we should be racing to better context prompting.
The bottom line: considering multiple perspectives
The Chroma research presents a compelling case against just relying on large context windows. Their data suggests the best models available today still struggle with simple tasks when presented with long contexts.
The key is understanding the tradeoffs and choosing the right tool for your specific problem, rather than assuming one approach is universally better.
Stop chasing bigger context windows. Start prompting smarter ones.
Get more frameworks like this
Practical AI strategy for executives. No hype, just real playbooks.
SubscribeYou might also like


The Likability Trap: AI Benchmarks Reward Charm, Not Value
The most popular AI benchmarks measure which model people like most, not which one is most useful. This has created a sycophancy epidemic, broken evaluation incentives, and a generation of teams picking AI tools the way we pick Instagram filters. Here's what actually matters, and how I use multiple models to get real work done.
