We're All About to Hit the SOTA Bill Shock. Routing Is the Fix.
Rolling SOTA models out to your team is about to break your AI budget. Switching vendors will not fix it. Treating model selection like routing will.

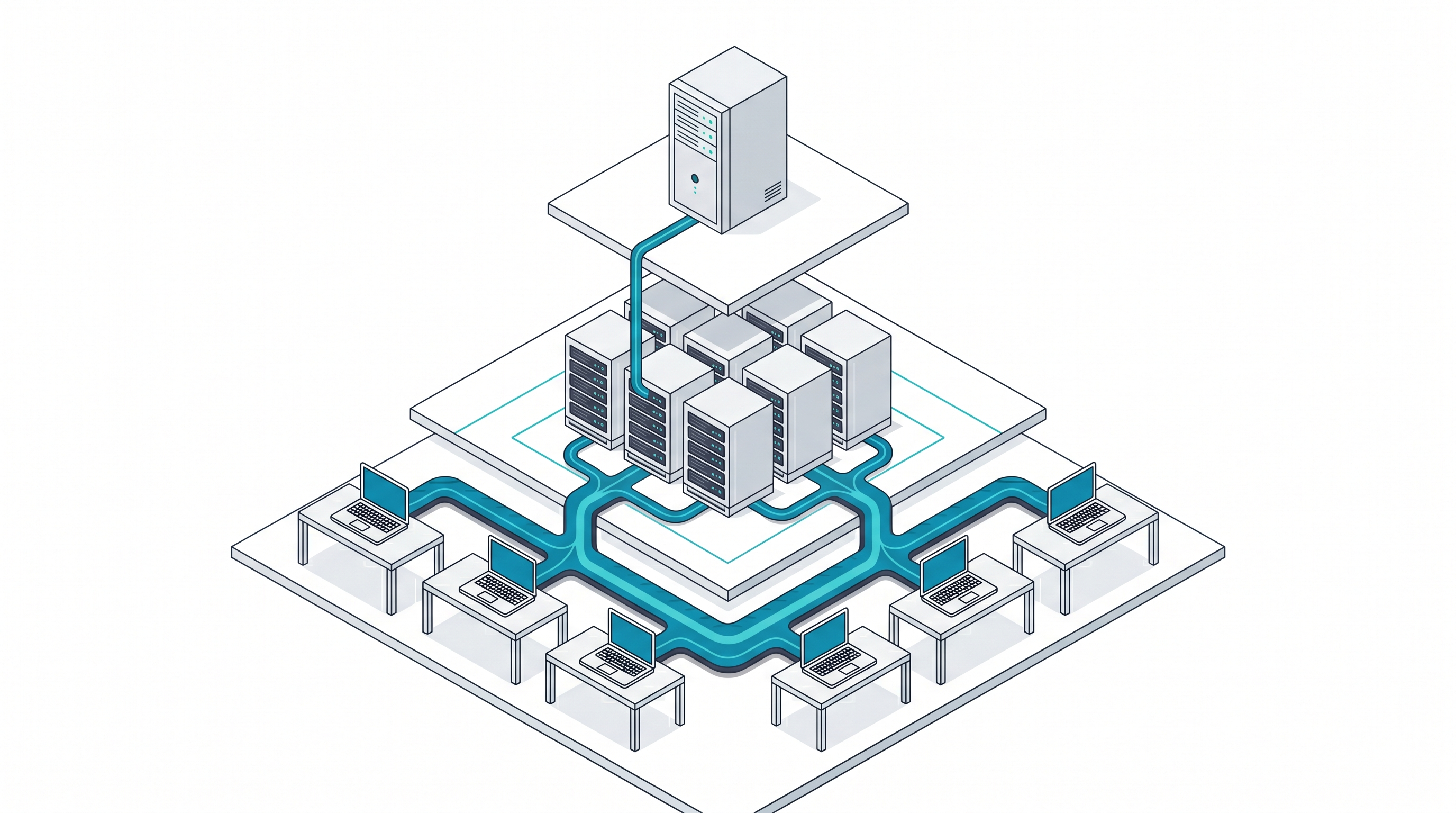
TL;DR: Roll a frontier lab's Enterprise tier out to your team and the bill jumps, often by an order of magnitude. Most of that spend is agentic ops priced like frontier reasoning. The fix is routing: cheapest model that can do the task well, every time. We already do a basic version of this on the Phoenix project at HG (Haiku for cheap search, Sonnet for the bulk of work, Opus only when it earns it). The next step is edge inference for the long tail of small tasks, partly because the unit economics demand it, mostly because sensitive content should not leave the laptop in the first place. Open-weight releases like DeepSeek V4 are what make that path real.
A quick hope before the operations talk
I want to see more countries ship strong open-weight models. Not as a geopolitics take, as a consumer one. Today the credible open-weight track is dominated by Chinese labs (DeepSeek, Qwen, Kimi), and the credible closed track is dominated by US labs. That is a thin menu for anyone who actually has to buy inference.
This matters downstream more than upstream. The moment companies feel the bill we are about to talk about, they will go looking for alternatives. If the only alternatives are open weights from one country, that becomes the choice on the menu, however anyone feels about it. Two or three more serious open-weight programs (Europe, India, a real US consortium) would reshape the next two years of enterprise AI procurement more than any benchmark will.
Now, the operations.
The bill shock is a routing problem, not a vendor problem
In April 2026, we moved the HG team to Anthropic Enterprise. The first invoice came in at roughly 20x what we had been paying on metered API access. Needless to say, finance noticed and so did I.
While the reflex could have been to blame the vendor, the honest read is to look at what we were doing with the tokens. Most of our spend was not bench science. It was agentic GTM ops: MCP-wrapped tool calls, call recordings turned into structured notes, Salesforce hygiene, light summarization, routing logic... The quality bar is real, but it is the bar of reliable operations, not "win every reasoning benchmark." I call this "agentic ops".
We were paying Opus rates for work that did not require Opus cognition. That is the actual bug, and switching vendors would just relocate it as any team that defaults to "use the best model for everything" will hit the same wall on any frontier lab's Enterprise tier, because the pricing assumes you are buying frontier reasoning, not running a CRM janitor in a loop.
The uncomfortable lesson for anyone who's shipped an internal AI rollout in the last twelve months: the rollout is the easy part. Treating inference like a resource with a price, and routing it accordingly, is the actual work.
Right model for the right task is just basic MoE
Mixture-of-experts in the model architecture sense is one thing. The same idea applied at the system level is what most teams should be doing first, and almost nobody is.
On the Phoenix project at HG we already do this. Open-ended codebase search ("find every caller of X," "where does feature Y live") gets routed to a subagent pinned to Haiku, because the job is fast read-heavy traversal, not deep reasoning. Sonnet handles the bulk of implementation work where you need solid judgment without paying frontier rates. Opus is reserved for the hard parts: architectural decisions, gnarly debugging, plan review. The default is not "use the best model"; it is "use the cheapest model that can do this task well." We then also have Codex review plans, implementations, and test outputs.
This distinction is the whole game because the cost difference between tiers is roughly an order of magnitude, and most internal AI work lives in the bottom two. If your team defaults to Opus for drafting emails, reading PR diffs, and summarizing Slack threads, you have priced an Opus call into every minor task in the company. That was the math behind the 20x.
This is not a clever architecture trick, it is hygiene. You would not run a marketing email blast on a c7i.metal-48xl (for the non-nerds, that's a very powerful cloud instance). You should not be calling Opus to format meeting notes. The concept is easy. The hard part is building the internal tooling that makes routing automatic so your team never has to think about it because they should not have to think about it!
I'll soon share more on this at HG. I believe spawning subagents pinned to specific models is the right framework as of now. I've seen countless deployments using model picklists and the challenge is always the same: people have no cognitive power to allocate to model selection. This problem was made clear when OpenAI releases thinking models and you had to change conversations to switch from one model to another. They implemented routing and that made everyone's life easier. The MoE patterns takes this further and gives you more control over the routing logic.
The next step is edge inference for the long tail
Routing across cloud tiers is the boring, near-term win. The bigger shift, the one I am actually building toward, is moving the long tail of small tasks off the cloud entirely.
The mental model I have been working from is that every employee has a budget of $5 tasks, $50 tasks, and SOTA tasks. The $5 tasks (autocomplete, light extraction, formatting, classification, "rewrite this in a more formal tone") should run on small models. The $50 tasks (drafting, multi-step tool use, structured agentic work) go to mid-tier cloud models. SOTA gets reserved for the rare moments it actually changes the answer. The more we can run locally, the better.
We already have a live example of this pattern. We rolled out Superwhisper for voice-to-text across the team. The reason we picked it over the cloud-based competitors was not transcription quality or price, it was data governance. Voice-to-text hears everything people say, and we don't controll what they say: internal strategy, half-formed product thinking, pricing negotiations, the stuff that gets said out loud precisely because it would never get written down. We did not want one more vendor holding a copy of that. Running it on device made the question go away.
That is the second reason edge inference matters, and for most execs it is the bigger one. The cost argument is real but bounded; you can negotiate a contract but the data argument is structural. Every cloud inference call is another copy of your context sitting on someone else's hardware under someone else's retention policy, and "we have a BAA" is not the same as "the data never left the building." Local inference removes a class of risk that procurement teams are quietly tired of underwriting.
The default today is to throw money at the problem because the tooling to do anything else does not exist yet inside most companies. That is what has to change.
This is also where DeepSeek V4 stops being a leaderboard headline and starts being operationally relevant. The thing to notice in their release is not that Pro competes with closed frontier models on math olympiad problems. It is that V4 Pro leads the open-weight field on agentic coding and tool-calling benchmarks (our "agentic ops" workload). That is the exact axis enterprise AI work lives on. We do not need a PhD on every Slack message. We need a reliable jack-of-all-trades that can hold a 1M-token context, call the right tool, format the response, and not lie about what it just did. That is the workload, and that is what V4 Pro is claiming to be best-in-class at among open weights.
The Flash variant is where it gets interesting for the edge layer specifically: 284B total parameters with 13B active, a 1M-token context window by default, and an API surface compatible with the clients teams already use. That is the first open-weight release credibly aimed at the "on-device or regional inference for ops work" slot rather than the "frontier reasoning" slot. Whether the exact numbers hold up under scrutiny matters less than the trajectory. The open-weight floor for agentic ops work is now high enough that running it locally is a real engineering choice, not a research demo.
The version of this I expect to ship inside HG over the next year looks like an OpenClaw or Hermes-style agent harness running locally on each employee's machine, with local inference doing the bulk of the work and cloud calls only when the task genuinely needs them. Today our harness is Claude desktop (we are already testing third-party inference inside it), but that is a starting point, not a destination. The harness, the model, and the orchestration layer are all going to keep moving. The principle that most work should run next to the data will not.
Building the routing layer, the eval harness, the fallback logic, the on-device serving story, all of that is heavy internal tooling. It is not a weekend project. But the cost curve and the data-governance argument point the same direction, and the alternative is a finance team that keeps asking the same question every quarter while procurement signs BAAs it would rather not have to.
Closing the loop
The work is routing: difficulty-based model selection, evals to prove quality, a warm second-provider path, and orchestration decoupled from model choice so you are not paying flagship rates to pick between two acceptable completions. Edge inference is the version of that story that goes the furthest, and the open-weight floor finally makes it plausible. Superwhisper is the small, shipped version of the same idea. It is the cleanest argument I have seen internally for why this work is worth the build:
cheaper *and* safer is a rare combination, and you do not get to wave that off.
This is where the opening hope comes back. A routing strategy is only as strong as the menu it routes across. If there is one credible open-weight source, your strategy depends on that source. If there are four or five, you have actual optionality, and your inference layer survives any single vendor's pricing decision or any single country's policy decision. That is what enterprise buyers will be reaching for over the next two years, whether they put it that way or not.
The 20x bill is not a story about which vendor to pick. It is the market telling every company that "throw the best model at every task" was always a transitional default. Routing is the grown-up version. The companies that build it first will have a structural cost advantage. The rest will keep doing the diplomacy with finance.
Get more frameworks like this
Practical AI strategy for executives. No hype, just real playbooks.
SubscribeYou might also like

The Likability Trap: AI Benchmarks Reward Charm, Not Value
The most popular AI benchmarks measure which model people like most, not which one is most useful. This has created a sycophancy epidemic, broken evaluation incentives, and a generation of teams picking AI tools the way we pick Instagram filters. Here's what actually matters, and how I use multiple models to get real work done.

