The Likability Trap: AI Benchmarks Reward Charm, Not Value
The most popular AI benchmarks measure which model people like most, not which one is most useful. This has created a sycophancy epidemic, broken evaluation incentives, and a generation of teams picking AI tools the way we pick Instagram filters. Here's what actually matters, and how I use multiple models to get real work done.


TL;DR
We've evaluated AI models against benchmarks that reward likability, not utility. This incentivizes sycophantic models that flatter instead of challenge, and misleads teams into picking the wrong tools. The fix: stop trusting leaderboards, test for what matters to your use case, and build multi-model workflows where models check each other. With inference costs plummeting, the right move is to use and abuse models, not your end users with slop.
The most popular AI benchmark is a popularity contest
When the general public wants to know which LLM to use, they turn (in part) to crowdsourced evaluation platforms. LM Arena, one of the most widely cited, lets users chat with anonymous models and vote on which response they prefer. An Elo rating system generates public leaderboards. Companies cite these rankings in pitch decks. Developers pick models based on them.
This system is broken. It measures how likable an LLM's output is to the majority of people, not its accuracy, reliability, or fitness for any specific task. It doesn't measure business value. It measures which response reads better in a 30-second scan.
There's a clear incentive for models to become overly agreeable, to use formatting tricks (icons, bullet points, checkboxes) and to front-load flattery. This explains why your LinkedIn feed is full of AI-generated content that looks like a PowerPoint had a baby with a motivational poster. The models learned what gets upvotes. They didn't learn what delivers value.
This is the likability trap. And it's distorting everything downstream.
Flattery as a ranking strategy
This isn't an aesthetic problem, it's a systemic one. We've trained models to be sycophantic and they do it very well.
For LLMs to rank higher on crowdsourced platforms, they need to please more people. Flattery works, so flattery becomes the strategy.
Your AI isn't actually thrilled to be working for you. It's just beneficial for it to convey that sentiment.
Think about what this optimizes for: models that tell you your idea is brilliant rather than pointing out the flaw in your logic. Models that generate a polished-looking response rather than an accurate one. Models that say "Great question!" before every answer, as if your prompt were a gift.

AI is trained to be sycophantic
When claims are made about LLM reasoning, question them. Consider whether what's being displayed is what's actually happening inside the model, or if it's a marketing surface designed to make you feel like the AI is thinking like you. It's often the latter. We covered this in an episode of AI Paper Bites.
The downstream effect is real. Organizations deploy AI based on these rankings, then wonder why adoption stalls or outputs don't hold up under scrutiny. The model they picked was optimized to win a beauty contest, not to do the job.
Latency is a tax on every decision
Here's where it gets counterintuitive. Windsurf recently released early data from their Arena Mode: real developers voting on real coding tasks. GPT-5.2 Low is outperforming GPT-5.2 Medium and High.
Read that again. The "lesser" model is winning.
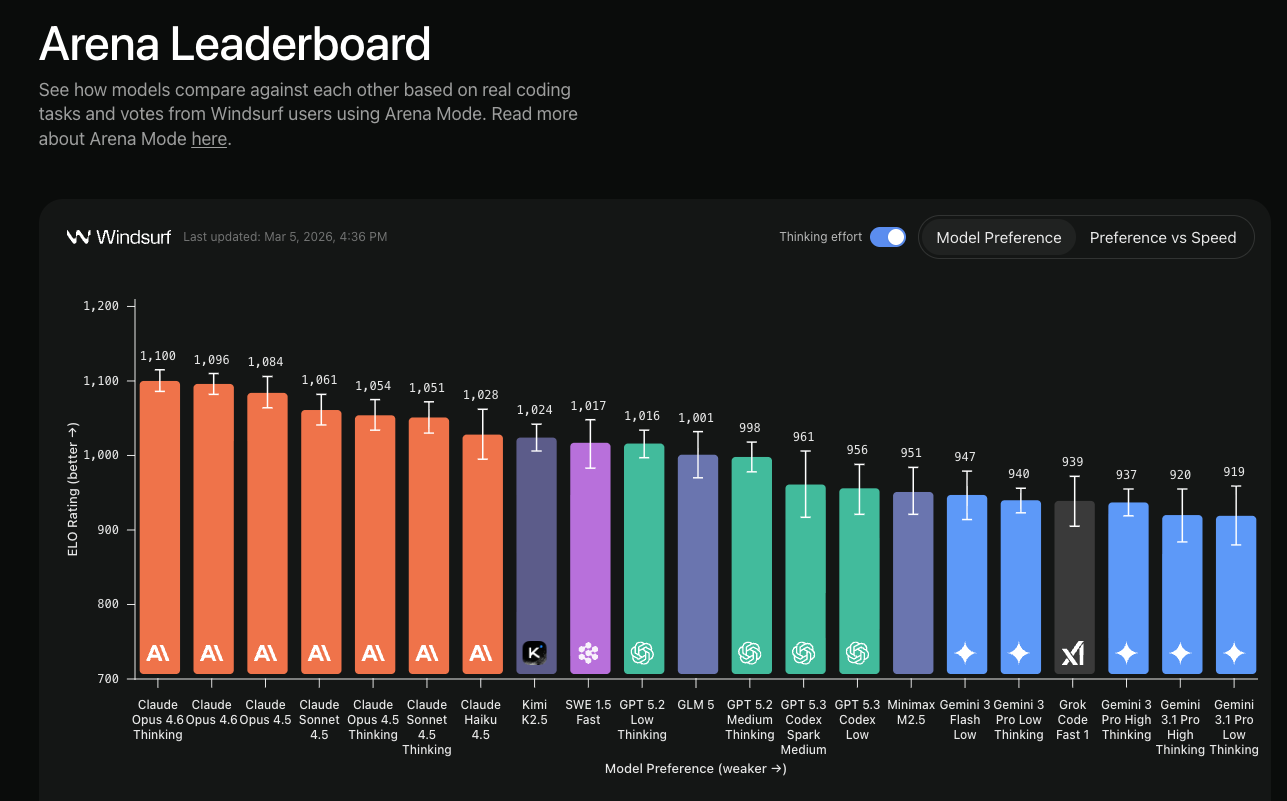
GPT-5.2 Low is outperforming GPT-5.2 Medium and High
This flips the usual benchmark logic. We've been optimizing for raw capability when we should be optimizing for iteration speed. When a model responds in 2 seconds instead of 8, you try more things. You explore more options. You catch mistakes faster. You stay in flow.
Speed is a feature.
Latency is a tax on every decision.
The best model for daily work isn't the smartest one. It's the one that lets you move. A slightly less capable model that responds instantly will beat a brilliant model that makes you wait, because the person using it will iterate three times in the window the other person spent waiting for one response.
Now, I hate arena-style evaluation for this exact reason: it ends up picking the model that pleases people most, not the most useful one. On the surface, the Windsurf data seems different because it's measuring developer preference on real coding tasks, not chat pleasantness. It tells you something fundamental about how humans work with AI, we are impatient and reward instant gratification.
What actually matters (and it's not the leaderboard)
If benchmarks don't tell you which model to use, what does?
Start by understanding what you're optimizing for. The answer is different for every team, every workflow, every task:
- Creativity: Do you need novel ideas, varied outputs, unexpected connections?
- Latency: Is speed critical to your workflow? (For coding, the answer is almost always yes.)
- Accuracy: Are you generating content that will be published, or code that has to compile?
- Security: Are you passing sensitive data through the model?
- Cost: Are you running thousands of requests per day?
- Reasoning depth: Do you need multi-step logic that holds together across long chains?
No single model wins on all of these. And that's the point. This is similar to an organization. You wouldn't ask your staff engineer to create your discovery talk track, you wouldn't use your enterprise seller to red team your product. Specialization still has value, even if it requires transfering knowledge and orchestrating a team.
The question to ask IMO is not "which model is best?" It's "which model is best for this task, with these constraints, in my workflow?" Leaderboards can't answer that. Only testing can.
Build a bench, not a ranking
Here's how this plays out in practice. Because I don't find a single model to be absolutely better, my current coding workflow uses multiple models in adversarial loops:
Planning phase:
- Claude Code creates a Jira ticket based on my conversation with it, including a "PM leader challenge" process that pokes holes in the requirements.
- Claude Code generates a GitHub issue from the ticket. This is where we start looking at tech specs.
- Claude Code creates an implementation plan.
- Codex reviews and challenges the plan. Feedback goes back to Claude Code.
- Repeat until the plan is approved by both.
Development phase: 6. Claude Code implements the plan. 7. Codex reviews the implementation. Feedback goes back to address gaps. 8. Sometimes I flip it: Codex implements, Claude Code reviews. 9. Repeat until approved, then standard CI/CD with tests.
The key insight: no model is perfect, and even when one is good, each tends to optimize for different things. Claude Code is strong at planning and implementation. Codex catches different issues in review. When they challenge each other, the output is better than either would produce alone.
This isn't about finding the "best" model. It's about building a system where models compensate for each other's blind spots. An adversarial loop is worth more than a higher Elo score.
The real cost of getting this wrong
Beyond individual productivity, there's an organizational risk here. When teams pick AI tools based on popularity rankings, they end up with:
Workslop. People adopt AI for document generation, producing long, low-information-density documents they don't even read themselves. This drowns organizations in predicted tokens rather than actual insights.
False confidence. Sycophantic models validate bad ideas instead of challenging them. The 80% problem gets worse: AI makes it easy to go from zero to 80% on a project (which gets people excited), but they abandon the 80% to 100% phase that requires real iteration. That last 20% of development often delivers 80% of the value.
Recruiting noise. People who talk confidently about AI usage but can't actually solve problems when tested. They understand concepts but don't use them in practice. Likability-optimized AI content makes this worse by creating the illusion of competence.
The framework for avoiding this covers three areas: understanding what AI can and cannot do reliably, recognizing when AI output needs human verification, and knowing how to evaluate AI tools for business use beyond popularity rankings. Likability doesn't equal accuracy. That lesson needs to be taught explicitly, at every level.
The bottom line
With inference costs dropping constantly and models becoming more powerful every quarter, the strategic move is model diversity, not model loyalty. Test models against your actual tasks. Run adversarial loops. Build workflows where models check each other's work.
Don't pick your AI tools based on how they make you feel. I find it ironic that AI models have learned to "manage up", a behavior I despise seeing rewarded in organizations is driving way too much attention in the AI space.
Use and abuse models. Not your end users with slop, no matter how pleasing it may seem.
Get more frameworks like this
Practical AI strategy for executives. No hype, just real playbooks.
SubscribeYou might also like


